embedding, text mining, bag of words
Document embeddings vs. Bag of words
Ajda Pretnar Žagar
May 30, 2024
A new video in our Text Mining series describes document embeddings, a text vectorisation technique that captures the semantic meaning of words. Let us see how document embedding differs from a bag of words approach.
1. Context
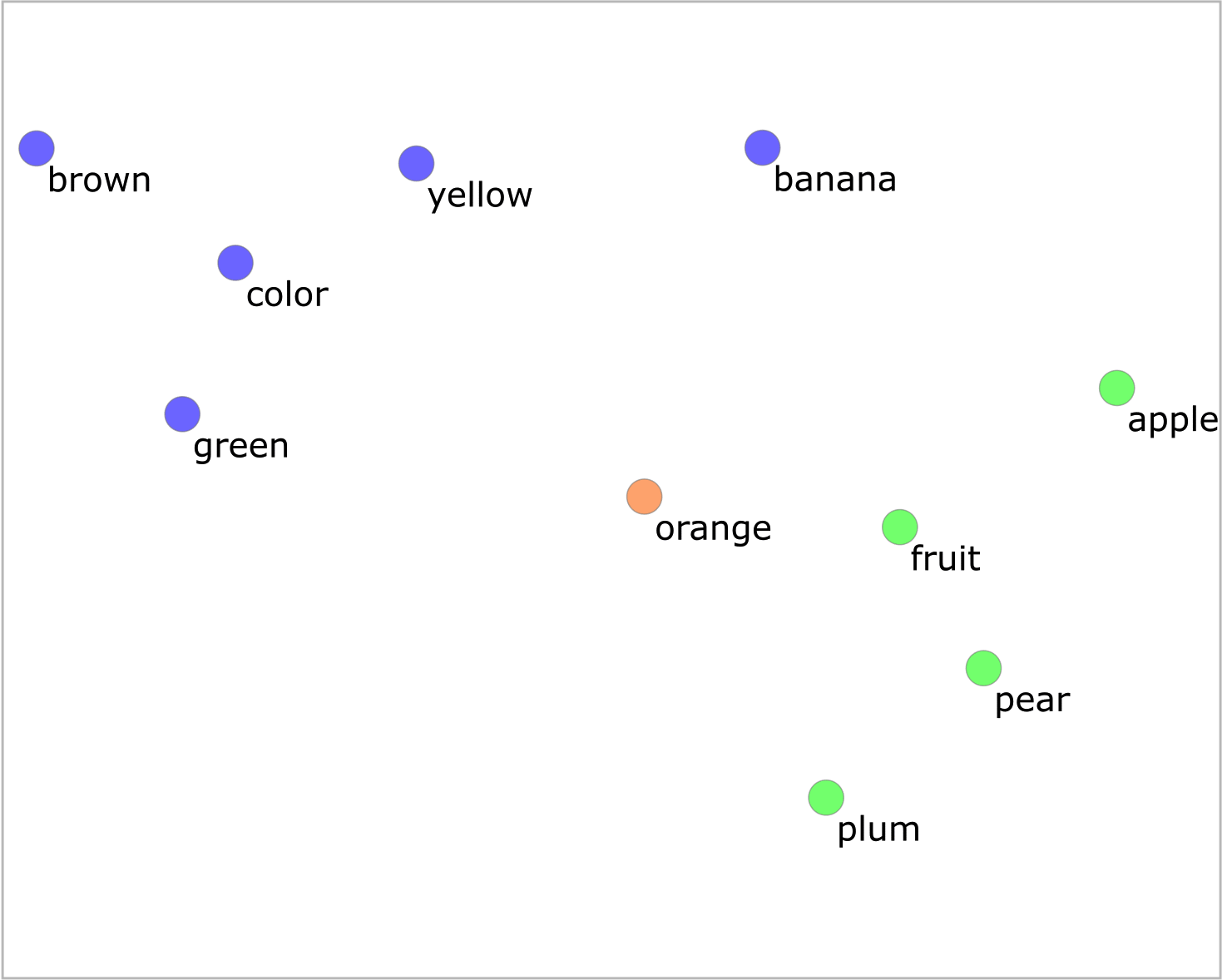
Document embedding considers context, particularly the SBERT model. For example, a bag of words approach cannot distinguish between the word "bear" in the following sentence: "A bear struggles to bear its weight." We might solve this in a bag of words by adding part-of-speech tags to the two words, i.e. bear_NOUN and bear_VERB. How about this one: "The orange was orange." The first "orange" refers to a fruit, while the second orange refers to a colour. Document embedding can consider context and distinguish between words with the same spelling (polysemy). Bag of words also does not consider word order, while document embedding does.
2. Fixed vector size
A bag of words can get prohibitively big when the vocabulary is large since each word is a feature. We can solve this by lemmatisation and filtering, but we might lose relevant details. Document embedding provides vectors of fixed length, making downstream analyses quicker.
3. Preprocessing
Preprocessing is key to control the vector size and to limit the noise in the data. Preprocessing before document embedding can be beneficial, but it isn't strictly necessary. In Orange, where we use pre-trained embedders, preprocessing is less important than if the embedding is trained from scratch.
4. Out-of-vocabulary words
A bag of words handles out-of-vocabulary words by constructing a column with the new words. However, since the word doesn't occur in the training data, the model won't consider it. On the other hand, embeddings typically rely on the subword information, which can infer information from out-of-vocabulary (OOV) words. FastText, for example, uses character n-grams to compute word embeddings, while SBERT uses WordPiece information. Both handle OOV words.
5. Interpretability
The biggest flaw of document embeddings is that they are not interpretable, while the bag of words features are. If interpretability is important, bag of words is the right approach. Document embeddings can become interpretable in Orange by using t-SNE for document maps and adding an Annotated Corpus Map to find keywords in document clusters.